Abstract
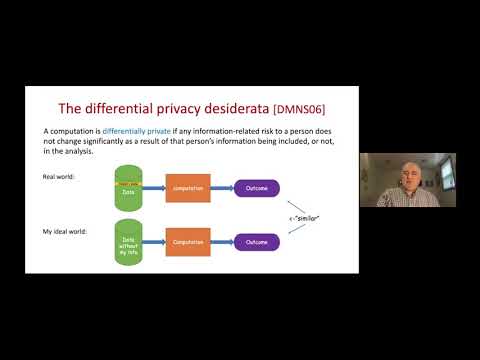
There are significant gaps between legal and technical thinking around data privacy. Technical standards such as k-anonymity and differential privacy are described using mathematical language whereas legal standards are not rigorous from a mathematical point of view and often resort to concepts such as de-identification and anonymization which they only partially define. As a result, arguments about the adequacy of technical privacy measures for satisfying legal privacy often lack rigor, and their conclusions are uncertain. The uncertainty is exacerbated by a litany of successful privacy attacks on privacy measures thought to meet legal expectations but then shown to fall short of doing so. In this work, we ask whether it is possible to introduce mathematical rigor into such analyses to the point of making and proving formal “legal theorems” that certain technical privacy measures meet legal expectations. For that, we explore some of the gaps between these two very different approaches, and present initial strategies towards bridging these gaps considering examples from US and EU law.
Based on work with Aloni Cohen