Contrastive Learning, multi-view redundancy, and linear models
Presenter
April 12, 2021
Abstract
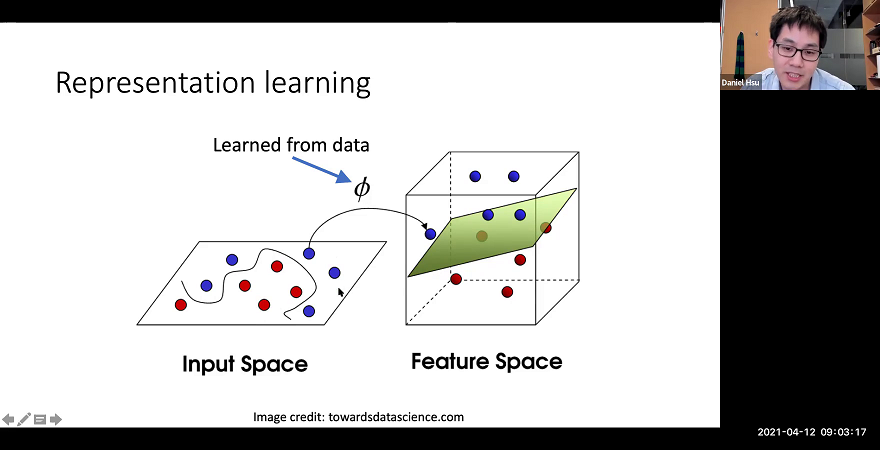
Contrastive learning is a “self-supervised” approach to representation learning that uses naturally occurring similar and dissimilar pairs of data points to find useful embeddings of data. We study contrastive learning in the context of multi-view statistical models. First, we show that whenever the views of the data are approximately redundant in their ability to predict a target function, a low-dimensional embedding obtained via contrastive learning affords a linear predictor with near-optimal predictive accuracy. Second, we show that in the context of topic models, the embedding can be interpreted as a linear transformation of the posterior moments of the hidden topic distribution given the observed words. We also empirically demonstrate that linear classifiers with these representations perform well in document classification tasks with very few labeled examples in a semi-supervised setting.